
Estimated reading time: 9 minutes
“You’re not perfect, sport. And let me save you the suspense. This girl you’ve met, she isn’t perfect either. But the question is whether or not you’re perfect for each other.”
— GOOD WILL HUNTING (1997)
It’s comin’! That season that journalists predict will be a wild ‘Summer of Love’, when hordes of singles starved for IRL human contact break free from their pandemic-imposed prisons to rendezvous with potential love interests at newly reopened bars and restaurants. Rusty from months spent navigating the idiosyncrasies of Zoom etiquette, they’ll invariably default to that age-old, boring, time-filler question, posed to determine if the person across from them might be a good match: “Hey, what’s your type?”
First of all, never ask that question because your attitude should always be, “*I’m* her type – she’s just never had the pleasure of meeting anyone quite like me before today” (but that’s a topic for another article on another blog). More importantly, typical responses rarely mirror reality anyway. Whether due to cognitive blind spots or pressure to project a good image, we all tend to reply with a standard list of idealized traits of some fictional character to whom we’d like to believe we’re drawn. A better way to discover someone’s “type” might be to have them describe their last few serious relationships – it’s an indirect way to hold them up to a truth mirror under unforgiving lighting.
These awkward dating interactions remind me of the CPU Benchmarking industry. After a new chip release, consumers and IT professionals rush to devour head-to-head benchmark reports from vendors and tech ezines, then engage in religious verbal warfare on reddit. Some go the “What’s your type?” route by reading marketing slides and articles straight from vendors. Others wait for independent sources to post (ostensibly) impartial results after running each CPU through a battery of application benchmarks – i.e., getting the vendor to reveal the quality of their past few (application) relationships. Which route better informs purchasing decisions? Is either optimal? If not, is there a better option?
Table of contents
Vendor CPU Benchmarks
Marketing for new CPUs naturally includes benchmark comparisons with rival offerings, using frameworks like CineBench, SPEC, SysMark, and others. Chip vendors hire the best engineers from around the world who certainly understand the nuances of benchmarking. So what could go wrong trusting their writeups? Plenty, actually. The term “benchmarketing” wasn’t coined for nothing.
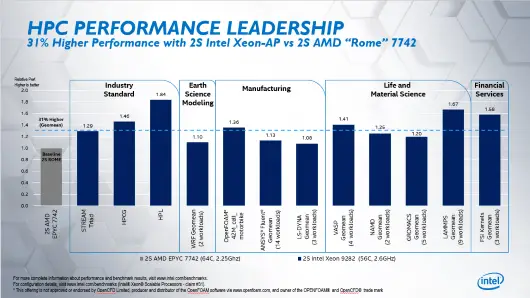
Recent history is replete with tales of vendors gaming benchmarks to obtain outsized scores. Back in ‘93, The Standish Group accused Oracle of adding a special option to its software for the express purpose of inflating its TPC-A score. While recent scandals may not be as egregious as those in the GPU industry, CPU vendors haven’t been angels, either. In 2017, online rumblings surfaced regarding whether AMD had purposely gamed CPU-Z for the Ryzen release. Meanwhile, Intel has long been accused of crippling the competition in head-to-head benchmarks via the dispatch functionality of its development tools.
Tactics aside, temptation to optimize your product yet devote minimal effort on a rival’s weighs on the most honest vendor. We read Yelp or OpenTable reviews instead of those directly from the restaurant for this vey reason. And that brings us to the other popular means of digesting benchmarks: independent sources.
Independent CPU Benchmarks
Tech ezines abound for CPU benchmark reporting. Each pit rival chips against each other in a gauntlet of tests with results highlighted in pages of bar graphs. On the surface, this offers a better alternative due to lack of bias. End of story, right? Nope, not by a long shot. Why? Because benchmarking is hard and time-consuming to get right. And if common pitfalls of experimental design and statistical analysis are not understood, it’s easy to mislead or be misled.
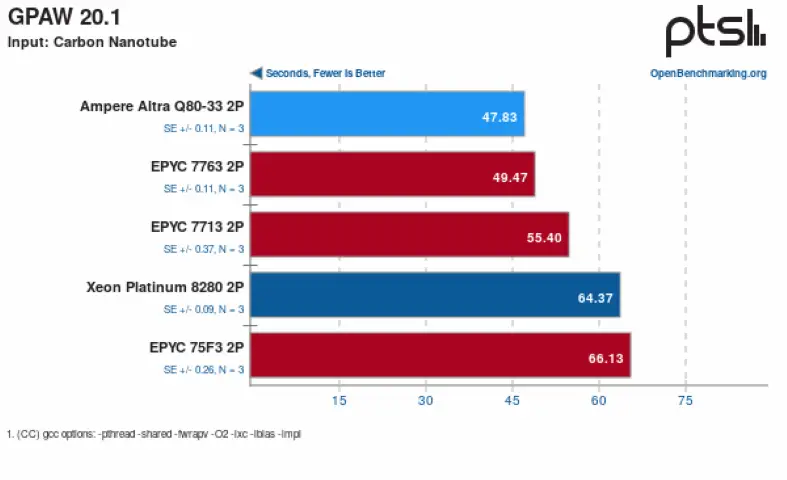
And it’s not only beginners who fall victim – professionals get it wrong, too. In “A Nine-Year Study of File System and Storage Benchmarking”, researchers found “that most popular benchmarks are flawed and many research papers do not provide a clear indication of true performance.” Similarly, in “Scientific Benchmarking of Parallel Computing Systems” authors concluded that “investigation of a stratified sample of 120 papers across three top conferences in the field shows that the state of the practice is lacking.”
Where do these independent bodies tend to go wrong when conducting performance benchmarks? It broadly breaks down into the following categories:
- Workload Quality
- Benchmark Execution
- Benchmark Reporting
Workload Quality
Workload Quality is where it all starts. If it’s not a representative workload, there’s no foundation upon which to base any dispositive conclusion. Geoff Tate, CEO of Flex Logix, bemoaned the continued use of the ResNet-50 benchmark in the Inference Chip market despite its native image size of only 224 x 224 pixels in a world of megapixel images. James Bornholt wrote about the common practice of using outdated SPECjvm98 and SPECcpu2000 benchmarks despite their growing irrelevance.
He highlighted another paper, “Power Struggles”, in which “lighthttpd” served as a benchmark despite completing in only 47ms. A more recently uncovered test duration issue involved a Redis benchmark from Phoronix v9.6.0 that completed in under 1 second. Short duration tests ignore the thermally adaptive nature of today’s CPUs which mandate longer runtimes to overcome attendant measurement biases.
Lastly, score weighting changes between benchmark suite releases can reduce real-world applicability, like with the GeekBench v5 release.
Benchmark Execution
Benchmark Execution is in an even worse state. In his book “Systems Performance: Enterprise and the Cloud”, Brendan Gregg explains the difference between passive and active benchmarking.
Passive Benchmarking
Passive Benchmarking is a “fire-and-forget strategy – where the benchmark is executed and then ignored until it’s completed.” This approach blinds the tester to issues like benchmark software limitations and bugs, resource constraints unrelated to the target, configuration limitations, and sources of measurement bias. It also conceals issues with benchmarks that test something completely different than advertised. Gregg details his experience testing disk I/O performance with Bonnie++, only to discover it barely tested disk I/O at all. Many tech ezines employ this passive approach. They fire off a wide range of benchmarks and display pages of bar graphs, sometimes accompanied by superficial explanations.
Active Benchmarking
On the other hand, Active Benchmarking includes low-impact observability tools to monitor the system under test (SUT) while benchmarking. This methodology avoids Passive Benchmarking gotchas *and* allows for insightful analyses and explanations of SUT and/or benchmark performance limiters. One of the best examples of this is Trevor Brown’s R.A.R.E. benchmarking methodology, where the ‘E’ stands for Explainable.
Narrowly Focused Scope
Lastly, independent testers overlook the importance of the entire CPU ecosystem when assessing chip performance. In fact, an entire industry has emerged (e.g., companies like Granulate and Concertio) based on the significant impact that compilers, libraries, build/link options, and OS configuration exert on processor performance. In misguided attempts at apples-to-apples comparison, many outlets benchmark rival CPUs on pathologically identical settings. The same OS with mostly default settings running software compiled with the same compiler & version using identical build/link options. But this completely disregards the complex interplay between these elements that offer unique performance implications across distinct CPU microarchitectures.
It’s like arranging a 100m sprint between the shorter Maurice Green (5’9” 165lbs), more prototypical Justin Gatlin (6’1” 183lbs), and lankier Usain Bolt (6’5” 207lbs). Imagine insisting on a fixed strength & conditioning routine, technical coaching, training protocol, and diet regimen for all three. Sure, it will be an apples-to-apples race. But if denied custom training for their unique body types, strengths, and weaknesses, will we learn who truly is fastest? Factor in that many benchmarks use default BIOS settings and it’s more like staging a race on a cobblestone road. In contrast, independent organizations like STAC engage vendors directly for SUT optimization assistance to obtain more accurate, realistic benchmark results.
Benchmark Reporting
Benchmark Reporting is the most pervasive problem, perhaps because it requires a foundational grasp of the nonintuitive study of statistics. How should I summarize a series of benchmark runs? Or a series of runs across different benchmarks? Which “mean” should I use? For instance, an asymmetric path of 40Gb/s and 10Gb/s mistakenly might be averaged at 25Gb/s instead of 16Gb/s (harmonic mean). In “How to Not Lie with Statistics”, Fleming & Wallace describe the prevalent misuse of “arithmetic mean” for “geometric mean”.
Martin Floser challenged the absence of run counts and standard deviation in “Why I Don’t Like Game Rendering Performance Benchmarks”. Despite much progress since then, the practice of reporting geometric means without indication of variance remains widespread. As Fleming & Wallace noted: “However, it should be made clear that any measure of the mean value of data is misleading when there is a large variance. For this reason, we feel that any meaningful summary of data should include some mention of the minimum and maximum of the data as well as the mean.”
Clearly, neither vendor nor 3rd party provided benchmarks offer a silver bullet. But is there a better option?
Perfect for Each Other?
We study CPU benchmarks in hopes that the workloads mimic that of our own application enough to aid purchasing decisions. For reasons outlined herein, such “determination at distance” is a fraught process. Hearing about relationship issues stemming from the unique alchemy of traits between your date and her exes is no substitute for sharing time together to discover what beautiful concoction might emerge from that between you and her. Likewise, perusing CPU benchmarks is no substitute for allotting time and effort to testing the CPU with your own application. Testing it in a realistic setting. Using all relevant configuration and tuning guidelines. Compiling against optimal libraries and recommended build/link options. Tapping the expertise of performance specialists.
Remember: you’re not any of her exes, and your application is not CineBench. Now don’t get me wrong: if he demeans the wait staff or tips poorly, then by all means excuse yourself, leave his DMs on ‘Seen’, and never speak to him again! And perhaps that is a more appropriate purpose for the more respectable benchmark publications – to serve as a 1st round pass to narrow the field of choices. But, to remix that famous “Good Will Hunting” movie quote:
“Your application is not perfect, sport. And let me save you the suspense. This CPU you’re looking at, it isn’t perfect either. But the question is whether or not they’re perfect for each other.”
