
Estimated reading time: 10 minutes
“When I started making music, I knew nothing about making music. I didn’t know any music theory; I didn’t know where C was on the piano. Since then, I’ve studied music. I used my new knowledge to create “Wu-Tang Forever” (the 7th Wu Tang affiliated album he produced), but it’s not as critically acclaimed. What does that tell you?
— RZA (one of the greatest producers in Hip-Hop history)
Widely regarded as the greatest hip-hop group ever, Wu Tang Clan contributed heavily to my life’s soundtrack. In fact, I still blast their single “Triumph” before every Conference Presentation I deliver. Robert Diggs, aka RZA, founded the seminal group in 1992, producing the majority of the group’s projects beginning with their debut album “Enter the Wu Tang (36 Chambers).” For six of the group’s initial releases, he had no formal music training – he was a vessel open to all possibilities as he experimented to find his distinctive sound which would earn him much critical acclaim. He mixed and arranged every track without the aid of a sound engineer:
“A lot of engineers went to school for this, so they’ll tell you, ‘If the vocals are at 2 kHz, your snare should be either above or below that so it doesn’t clash with the vocals.’ But I found that sometimes the snare has to clash with the vocals to punctuate them. You have to ignore the science of it, even the logic of it. Sometimes real discoveries take a leap in consciousness that’s outside the intellect.”1RZA, Chris Norris, The TAO of the WU (New York: Riverhead Books, 2009), p. 114-115
Yet, it was only after having received structured training that he first garnered mixed reviews. He believes that training put his mind in a mechanized or fixed state, thereby inhibiting his formerly receptive process. This phenomenon is so common that psychologists have a name for it: Einstellung Effect. It impacts individuals and groups alike. In this age of Agile Development, combating this psychological impediment and ensuring quality delivery requires vigilance. Last month, I wrote about a few of the benefits of Shift Left Performance for IT organizations. Today I will expound on its capability to mitigate the impact of Einstellung Effect. But first, let’s define it more fully.
Table of contents
What Is Einstellung Effect?
“In the beginner’s mind there are many possibilities, in the expert’s there are few.”
— Suzuki Roshi
If there’s an emotion you’ve ever experienced, more than likely the Germans have a word for it. Ever taken satisfaction in witnessing the comeuppance of an enemy? That’s schadenfreude. Ever gained weight after a bad breakup from sobbing on the couch while binge-eating ice cream or pizza? That’s kummerspeck. Einstellung is also from German, and translates to “attitude” or “setting” – it refers to the state of a mechanized mind. Einstellung Effect is a cognitive bias which describes the negative effect of prior experience when solving new problems. It creates a disposition to solve a given problem in a specific way despite the presence of more optimal alternatives. It was most famously illustrated by psychologist Abraham Luchins’ 1942 Water Jar Experiment,2Water-Jar Problem – https://www.oxfordreference.com/view/10.1093/oi/authority.20110803121257782 where he’d given participants the following test:
Given 3 water jars of sizes A) 21 units, B) 127 units, and C) 3 units, measure out exactly 100 units of water. Participants correctly figured that they’d fill B, then pour out enough to fill A, and then pour out enough to fill C twice, or B – (A + 2C).
After a subsequent series of similar tests, he then asked them to measure out exactly 18 units given 3 water jars of sizes A) 15 units, B) 39 units, and C) 3 units. 81% of participants replied with the same method used in the first test, B – (A + 2C), despite the fact that just adding jar A and jar C into jar B (i.e., A + C) would be much simpler. Their prior experience closed off their imaginations to the better solution.
Yet, of the participants who were never given the initial series of tests, 100% chose the simpler A + C solution. Their minds had not been mechanized by the prior experience of the first series of tests. Luchins proved that what you already know can hurt you.
InnoCentive is a company that was founded to combat this effect for organizations.3David Epstein, Range: Why Generalists Triumph in A Specialized World (New York: Riverhead Books, 2019), p. 173 Baffled after exhausting all domain-specific methods and solutions to solve an intractable problem, organizations can partner with InnoCentive to craft a Problem Statement in a form general enough to present to the public, which InnoCentive then publishes for “outside solvers” to review and offer solutions. Solvers whose solutions are chosen by the requesting organization reap monetary rewards. Most often, these “outside solvers” work in completely different industries from those of the Problem Statement authors. For example, one particular Problem Statement that originated from a group of chemists was solved by a patent lawyer.
InnoCentive has discovered an antidote to Einstellung Effect – namely, engaging minds from outside the specialized domain of the requester. Minds unburdened by the formalized study of the tools and techniques of the requester’s trade. Shift Left Performance Engineering exerts a similar impact in Agile Teams, which largely comprise Software Developers. While some overlap exists between Performance Engineers (PE) and Software Developers, they differ greatly in approach. Often, practitioners from within each field undergo completely different study curricula and career progressions. Disparate enough for PEs to provide an “outside solver” viewpoint to an Agile Team. Let’s consider a couple examples.
Example #1: Efficient Algorithms
Software developers specialize in the study and design of algorithms and data structures. They select or adapt them with acuity based on a design description. Pros and cons of each candidate algorithm are weighed based on computational complexity (expressed in Big O Notation). Decades of algorithm and data structure research transcribed into thick tomes instruct new crops of software engineers every year as they pour out into the worlds of Silicon Valley and FinTech.
However, while the substance of these books has remained largely unchanged over the years, computers have grown in complexity. We now have superscalar CPUs with ever-deeper pipelines, more powerful instruction sets, wider registers and vector processing capabilities, multi-level instruction and data caches, larger Translation Lookaside Buffers with varying page size support, intricate coherency protocols and traits, more complex branch prediction, and so on and so forth. In fact, CPUs have become so arcane that an algorithm with inferior computational complexity can outperform a theoretically better one.
A recent example is chronicled in Andrei Alexandrescu’s Keynote Speech at CppCon 2019 entitled “Speed is Found in the Minds of People” in which he detailed his attempts to improve performance for Insertion Sort over hundreds of elements. His first several attempts were successful at materially reducing the number of required operations. And yet, they all yielded paradoxically longer runtimes than vanilla Insertion Sort. Big O Notation is not the efficiency determinant it once was.
“Throw the Structures and Algorithm books away. Look at research papers and measure. That’s all we can do. The books are kinda weirdly out of date.”
— Andrei Alexandrescu
This is where PEs help break out of the mechanized mindset of Big O Notation. Most of them may not be able to rattle off the coloring rules for re-balancing a red-black tree. But they do understand CPU microarchitecture. They can look at a code snippet and guesstimate the impact it may exert on branch prediction or caching. Using relevant profiler tooling, they can then confirm or reject their hypotheses. They bridge the gap between the theoretical and the practical.
The situation is worse with data parallel algorithms, such as those used in graph processing. Though touted for supposedly superior “scalability”, they often exhibit far worse runtimes (in some cases by orders of magnitude) and resource efficiency4Efficiency Matters! – https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.160.3837&rep=rep1&type=pdf when compared to alternative non-parallel algorithms.5Scalability! But at what COST? – https://www.usenix.org/system/files/conference/hotos15/hotos15-paper-mcsherry.pdf In this age of cloud computing, this narrow focus on high scalability at the expense of high performance leads to expanding costs with every addition of an underutilized compute node to a cluster.
“You can have a second computer once you’ve shown you know how to use the first one.”
— Paul Barnham
Much of this is rooted in the persistent misconception that thread parallelism equates to high performance. Many in the IT community think in terms of Amdahl’s Law. This law describes the speedup achievable from application concurrency using the proportion of serial to parallelizable portions of a workload. The serial portion denotes its Contention Factor. Efforts to reduce the Contention Factor is evident from the proliferation of lock-free/wait-free algorithms and data structures.
On the other hand, PEs think in terms of Neil Gunther’s Universal Scalability Law (USL),6How to Quantify Scalability – https://www.perfdynamics.com/Manifesto/USLscalability.html which builds upon Amdahl’s Law by including the Coherence Factor – i.e., inter-thread data exchange. This latter factor can inflict a significant drag on multi-threaded performance in surprising ways if not accounted for. Some algorithms exhibit a high Coherence Factor by design, like the Paxos Distributed Consensus Algorithm. But even multi-threaded applications written without explicit inter-thread data exchange can experience an *implicit* Coherence Factor. For example, Cache Coherency Protocols (e.g., Intel MESIF or AMD MOESI) inflict it in the presence of false sharing.7CPU Cacheline False Sharing – https://people.redhat.com/jmario/scratch/NYC_RHUG_Oct2016_c2c.pdf
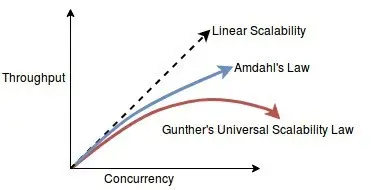
Developers understand from experience that writing “correct” multi-threaded applications is hard and debugging them is even harder.8Advancements in code analysis tools notwithstanding (e.g., compiler thread sanitizers) But PEs understand that parallelism can happen at other levels before venturing into thread parallelism. Today’s CPUs are capable of powerful instruction-level and data-level parallelism (e.g., SIMD), both of which are achievable in single-threaded applications. A PE’s grasp of CPU instruction sets enables him to examine and detect suboptimal code generation, which reduces instruction/data-level parallelism. This “outside solver” insight comes in handy in early Agile Team collaboration to ward off Einstellung Effect.
Example #2: Testing Methodology
Adequate testing in all phases of the Software Development Lifecycle is paramount to maintain quality in frequent release CI/CD environments. Agile Teams that adhere to Test-Driven Development (TDD) principles understand the long-term benefits of discipline for writing Unit tests first. Mature testing frameworks, for both Functional and Performance Unit testing (e.g., Google Benchmark, JUnitPerf, etc.), makes TDD compliance easier.
But a recurring problem is teams blindly re-purposing Functional Tests for Performance, only running them longer at fixed rates across more users. Likewise, in FinTech, where load typically includes exchange market data in the form of UDP multicast packets, many teams resort to replaying recorded PCAPs at fixed packet-per-second (pps) rates. On the surface this makes sense since this reflects how most simple Performance Unit Test frameworks operate. However, effective Performance Regression and End-to-End Load testing requires more analysis and workload characterization than at the Unit test level. A brief digression into the very basics of Queuing Theory will help explain why this is.
Queuing Theory is a foundational topic in Performance Engineering. It describes queues using 3 attributes: request inter-arrival rate, service time distribution, and number of services. Kendall Notation is employed as a shorthand to denote these attributes. For example, a queue with a fixed interval arrival rate (or D for Deterministic) and exponentially distributed service times (or M for Markovian) with only one request processor (1) describes a D/M/1 queue. Typical network services like Internet HTTP or UDP market data readers exhibit request bursts which more closely mimic an exponentially distributed9Although more recent research suggests that network traffic is more accurately modeled as “self-similar”.arrival process, or an M/M/n queue (‘n’ for the number of HTTP or market data reader services).
Queue behavior differs based on these attributes, as reflected in the differing response time formulae associated with each queue type. Intuitively this makes sense. You wouldn’t expect a restaurant owner to prepare for steady arrival of 30 customers per hour in the same way she would for the same rate but in 10-minute-long bursts.
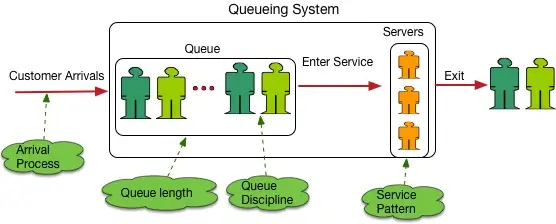
What’s the point here? It’s that re-purposing Functional Tests this way is relevant only for D/M/n queues, like a replayed PCAP at fixed pps. Expose that app to bursty Production traffic and you’ll discover drastically different response times than that measured in testing. End result? Nasty surprises, irate users, poorly performing trading strategies, and angry management. Including PEs early in the process (i.e., Shift Left Performance) shields against any tendency toward Einstellung Effect regarding testing methodology.
Shift Einstellung Effect Out of Your Team
Einstellung Effect is a counterintuitive bias in that the more experienced a team is, the more susceptible it becomes. Cultivating an “outside solver” presence on Agile Teams using Shift Left Performance Engineering will mitigate the negative effects of this common psychological hindrance, and facilitate what Suzuki Roshi described as ‘the beginners mind [where] there are many possibilities’ so that your clan can be just as prolific and formidable as that of the Wu Tang!
- 1RZA, Chris Norris, The TAO of the WU (New York: Riverhead Books, 2009), p. 114-115
- 2Water-Jar Problem – https://www.oxfordreference.com/view/10.1093/oi/authority.20110803121257782
- 3David Epstein, Range: Why Generalists Triumph in A Specialized World (New York: Riverhead Books, 2019), p. 173
- 4Efficiency Matters! – https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.160.3837&rep=rep1&type=pdf
- 5Scalability! But at what COST? – https://www.usenix.org/system/files/conference/hotos15/hotos15-paper-mcsherry.pdf
- 6How to Quantify Scalability – https://www.perfdynamics.com/Manifesto/USLscalability.html
- 7CPU Cacheline False Sharing – https://people.redhat.com/jmario/scratch/NYC_RHUG_Oct2016_c2c.pdf
- 8Advancements in code analysis tools notwithstanding (e.g., compiler thread sanitizers)
- 9Although more recent research suggests that network traffic is more accurately modeled as “self-similar”.
